
[Paper Explained] [AAAI2021] Structured Co-reference Graph Attention for Video-grounded Dialogue
Published:
Flow up to my brief introduction about video dialogue of the previous blog, today, I will into detail with one of these state-of-the-art approaches in this topic. The paper I wanna introduce is Structured Co-reference Graph Attention for Video-grounded Dialogue, Junyeong et al. published at AAAI 2021. On a high level, the authors proposed a bipartite co-reference structure to connect the information over multiple modalities (visual, linguistic), and then capture information from the complex spatial as well as the temporal dynamics of video via an attention graph. By representing underlying dependencies between modalities, this design has moved 1 step forward in the reasoning over language and visual.
Problem Formulation
For people who haven’t known about the video dialogue problem (and have not read my first blog) yet: “Given the video, the sequences of questions and corresponded answers (dialogues), and 1 following question, you suppose to answer that question fully and correctly”. All the questions in dialogue are about actions and events happening in the video, moreover, we have an assumption in dialogue is that the information from the previous questions and answers will not be repeated, therefore a good answerer must understand both video and sentences to give the most appropriate answer. In the example in Figure 1, the question uses the subject “he” referring for the man in the video. The answer of that question can be: “he appears to be neutral in expression”. As you can see, the video is kind of our normal daily record video, it has a lot of objects in the background, the quality is not too good and the perspective is not always include the main subject.

Architecture Overview
What contributions are this paper proposed? Look at the overview architecture on the Figure 2
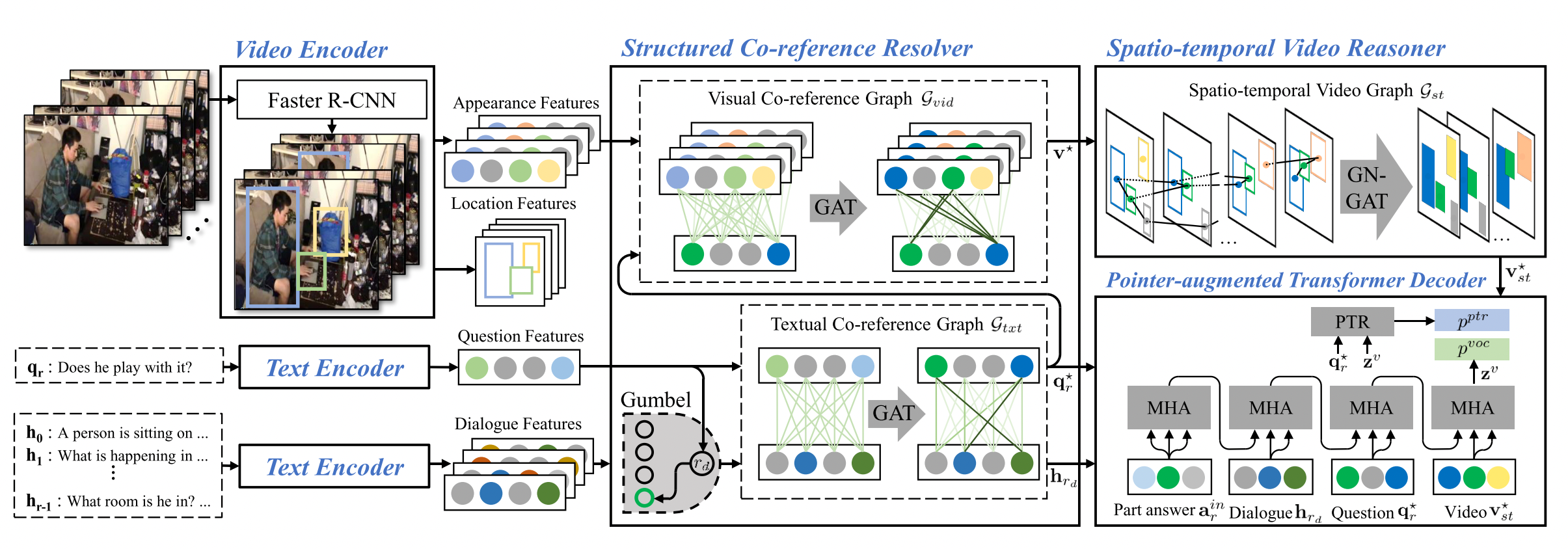
First of all video is split frame by frame, then be represented by the set of objects v, where each object in v includes an appearance feature vector and location feature vector which are extracted by Faster-RCNN (Video encoder). In the paper, the authors used 15 frames per video, and 6 largest objects from each frame.
Linguistic features (q and h) are got from the current question and the history (the previous pair QA in dialogue) explicitly. This paper implemented a token-level embedding layer to map sequences of words into higher dimensional representation.
In the next step, the set of video and linguistic features goes into the Structured Co-reference Resolver (this is sort of the magic blackbox Number 1, we will go deeper in the next part) and gets out the first aligned visual features v*, the first aligned question features q*, and the first aligned history features h*. I called them aligned features vector because it has exactly the same shape as well as representing the same kind of input as the original ones, but they have been aligned together with the question by the Structured Co-ref Resolver to become more useful for answering that question. For example, the aligned video features of the objects related to the question will now be emphazied or the same thing will be done in the aligned history features.
The v* is the input of the Spatio-temporal Video Reasoner (well, the 2nd blackbox we will go back in the next part of this blog) which try to reason over the information of different objects in the same frame (local context) and in the object features from different frames (global context) to produce v*st - the new representation of the video. This new representation together with the aligned history and question features is put through a Pointer-augmented Transformer Decoder to generate the answer response. This module is kind of the slightly modified version of the traditional Transformer Decoder with the additional dynamic pointer network to either decode tokens from fixed vocabulary or copy from question words based on the intuition that question tokens can form a structure of the answer. For example, “He [context verb] after closing the window” for the question “What does he do after closing the window?”
Structured Co-reference Resolver
So now let’s go into more detail about the magic blackbox components. Firstly, we will have a look into the Structured Co-reference Resolver. As I have briefly introduced in the overview, the purpose of this component is to align the features in the video, question, and history. In other words, connecting the information in different modalities and attend to the most related ones between them. As Figure1 illustrated, the authors tried to use 2 bi-partite co-structure to connect the linguistic information from the dialog and the visual features from the video with the question as the mediate (as Figure 3 below)
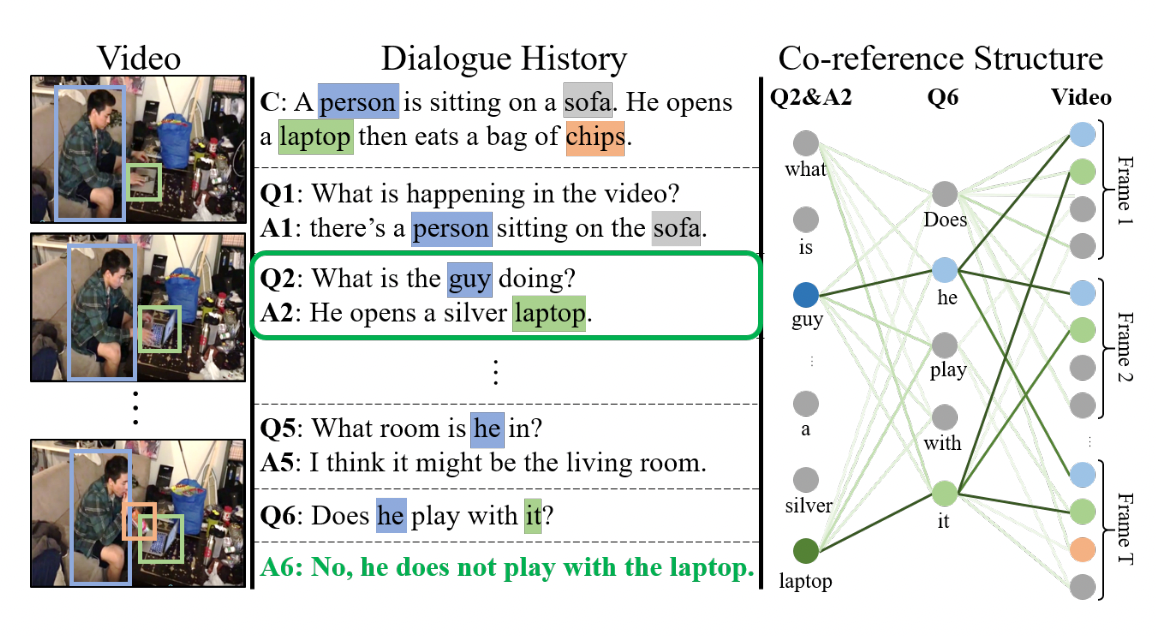
Textual Co-reference Resolution
In order to inject semantic information from the dialogue history into the question vector representation for textual co-reference resolution, the paper first determines a key dialogue history, and then lets question tokens attend to key dialogue history tokens. A Gumbel-Softmax was implemented for that function.
Gumble-Softmax is a continuous distribution on the simplex that can approximate categorical samples. In other words, it re-distributes the discrete distribution (one-hot-encoded categorical distributions) into the continuous distribution (dense distribution). Let me make it clearer, for example, we have a conversation including 10 pairs of QA, and we want to attend to one specific pair that related the most to our current question. This kind of attention is called “hard attention”. But usually, we want to attend to more than 1 pair (soft attention) because it seems more intuitively suited in reality (some pairs are more related than some others, so we want to attend to pairs with different levels). This mechanism is applied in the Self-Attention mechanism, where the module does not attend to a specific pair but takes a weighted sum of them. But sometimes, we want the approach that kind of in the middle of soft attention and hard attention. For example, we want our model to attend directly to a specific pair (which is too similar to our question) and weighted sum of the other. This is exactly how Gumble-Softmax works! The combination of two tricks.
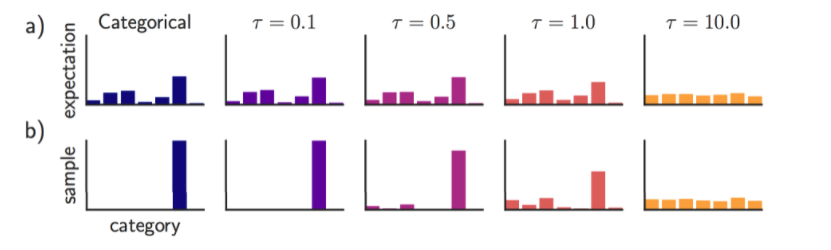
Figure 4 above illustrated how Gumble-Softmax redistributes our output. The bigger temperature is, the more similar our output with the weighted sum mechanism, on the other hand, the smaller temperature is, the more similar our results with the hard-attention mechanism.
The authors design the textual co-reference bi-partite graph Gtxt with nodes brought the information from question and each dialogue history. Graph attention is also applied to inject semantic information from history into aligned question features representation.
Visual co-reference resolution
The architecture of this co-ref structure is the same as the text co-ref one. A bipartite graph Gvid is created by treating all objects from video and token features from the question (which have just been aligned by history) as graph nodes.
At the end of this step, we have v, q, and h* as the representation of objects in video, question, and history respectively, which have each other related semantic information after the text co-ref and visual co-ref.
Spatio-temporal Video Reasoner
Secondly, After emphasized features from the most related objects with the current question and the history, the paper proposes one further step to align the visual features using Spatio-temporal Video Reasoner (The 2nd blackbox). This component is a spatio-temporal video graph Gst that models the relationship between detected objects over frames. The key here are modelling the relationship between detected objects over frame (spatial) and the same object between different frames (temporal). A graph edge is constructed as the equation (13).
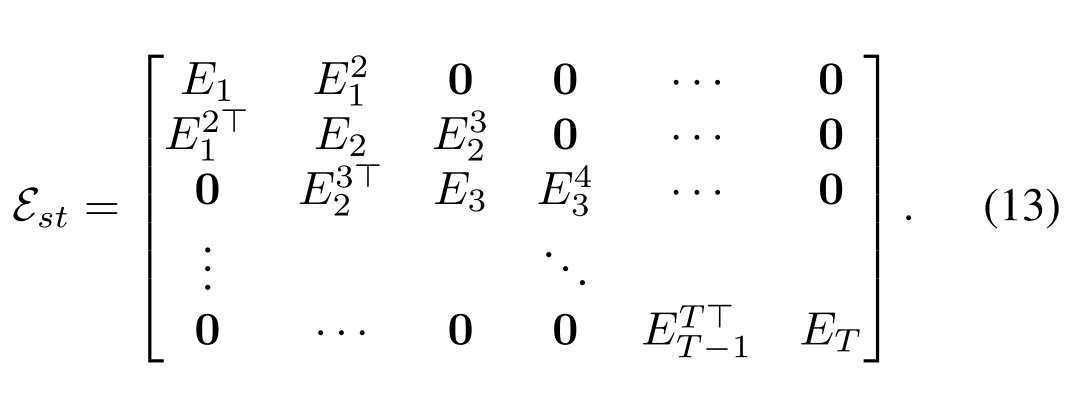
Here, authors used the location features of objects to object Et and Ett+1. More detail, with spatial representation, Et[i, j] = 1 if i-th object and j-th object in frame t are close enough. On the other hand, with the temporal relation, Ett+1[i, j] = 1 if i-th object in frame t and j-th ob- ject in frame t + 1 are close enough and have same object label.
Results
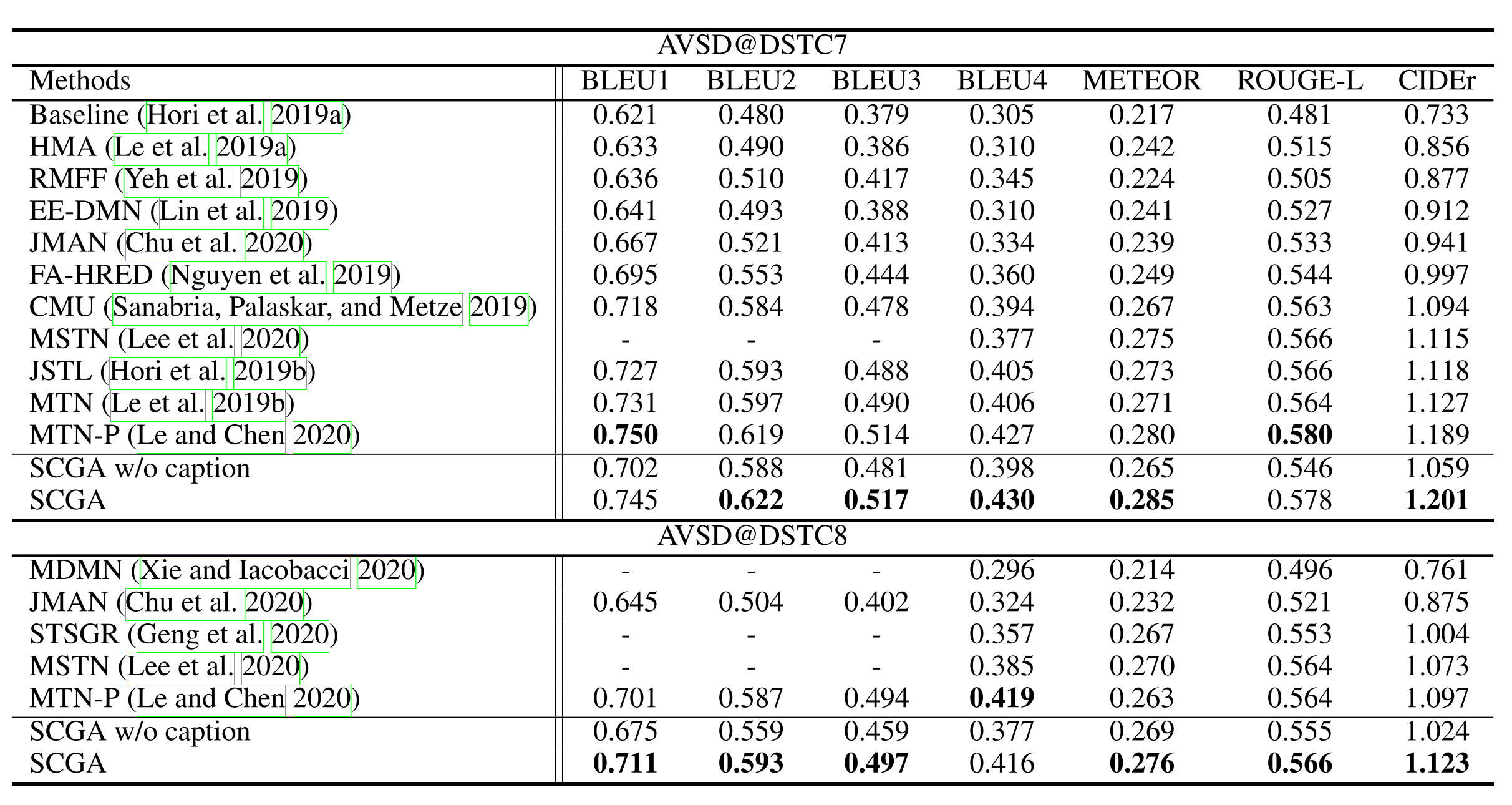
The number comparing the proposed work and other state-of-the-art methods are reported in Table 1. The proposed method works very well and have the higher BLEU, METEOR and CiDER score on the AVSD-DSTC7 and AVSD-DSTC8 dataset. Actually, the improvement is not too much but this is a very creative approach containing an explicitly reasoning path (what I mean is we can explain why our model generate this answer, where they focused on from the video or which information from the history they used the most…).
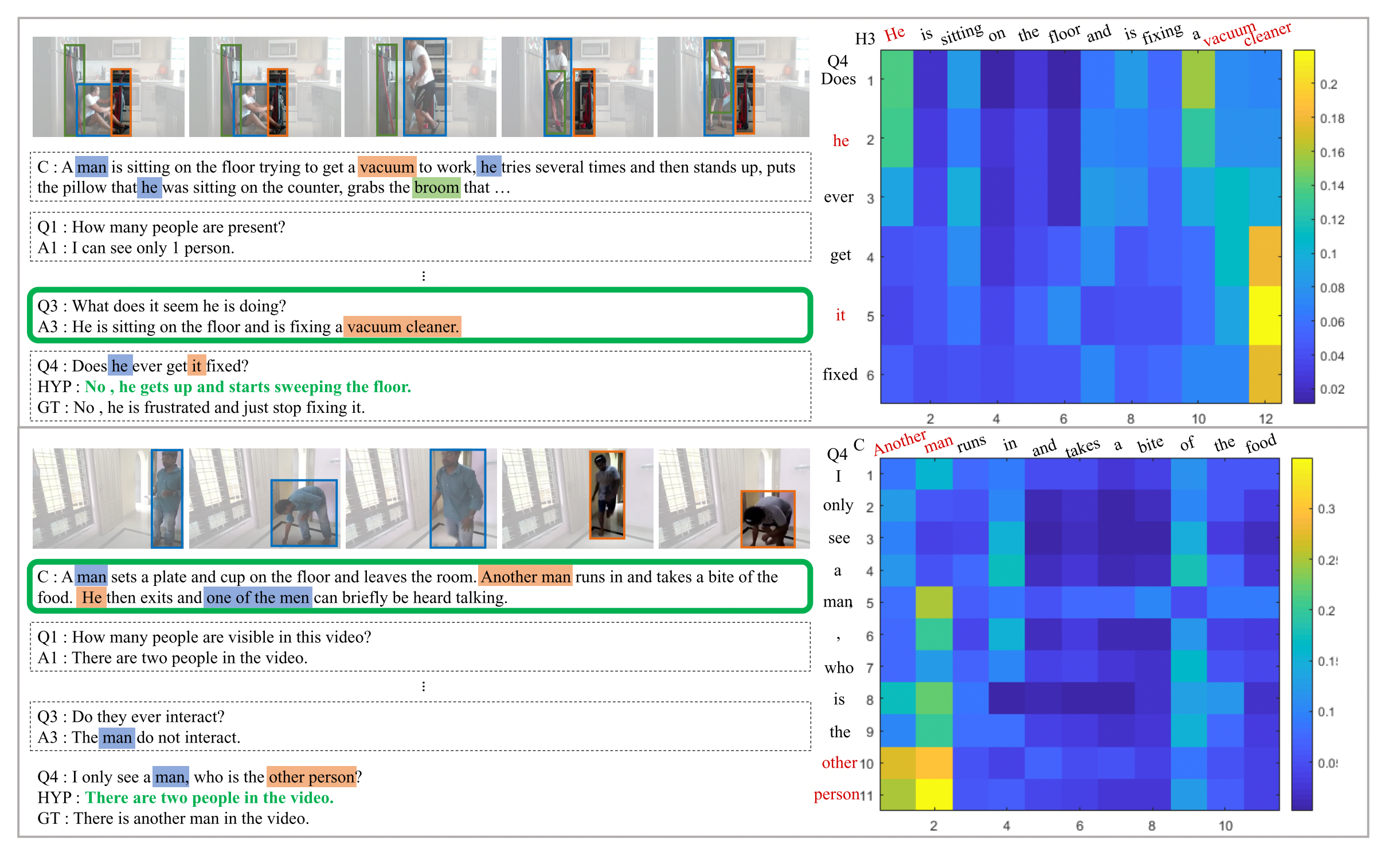
The authors also provide the visualization of their model to measure the effectiveness of proposed method in the Figure 7 below.
Thank you
Thanks for reading! Feel free to contact me if you have any suggestion/ comment for my blog.
Hoang-Anh
